If you manage an on-prem Splunk Enterprise environment, you will often have to check to make sure that everything is performing optimally. The primary limitations to your environments search capacity will be the IOPS of disks in your Indexers (Search Peers) and CPU/Memory of your Search Heads. As long as your meeting the Splunk requirements for IOPS, then the Indexer side should be sufficient. In most cases, if you are still have search issues related to the Indexers, add more Indexers, i.e., scale out rather than up in most cases, but most importantly, meet the IOPS requirements. As for the Search Head, this can benefit from both scaling up, out, and adjusting your Splunk configurations depending on what’s available to you. When Splunk is under-performing, it can become a good idea to review the following:
- Review Data (Im)balance
- Assess Disk Performance
- Identify Slow Indexers
- Assess CPU/Memory Performance
- Guesstimate Scheduled Search Capacity
1. Review Data (Im)balance
Run the below search over the last 24 hours to check for data imbalance. Below are sample screenshots of both good and bad data imbalance scenarios. The search shows the number of events being indexed by each of your Splunk indexers. To keep things visually clear, this environment comprises 4 non-clustered indexers.
To begin remediating, I would try to identify any problematic indices first, and then taking steps to narrow down if there are just a few forwarders or sources that are responsible. At that point, it should be much easier to identify whether there is a misconfiguration, most likely in the outputs.conf or props.conf file.
| tstats count where index=* by span=1s _time splunk_server | timechart span=1s useother=false sum(count) by splunk_server
Good Data Imbalance
When data is balanced, you should see events spread relatively evenly and few spikes. This means data is breaking evenly and being evenly distributed to your indexers.


Bad Data Imbalance
With bad data imbalance, you can see spikes of events going to a single indexer or two at a time. In the below example, there is a lower line around 150, which shows good looking data distribution. However, there is a line around 500, which clearly shows that one log source is not breaking events properly. In this example, it is a single poorly configured forwarder. This is not the worst scenario, but not ideal. The more spikes and inconsistencies, the worse the data imbalance problem may be in your environment.
Even if there is no single source of the issue, a natural imbalance can occur over time. If so, then you should still customize the outputs.conf settings for your environment. Once your incoming data looks more balanced, then you can rebalance the existing data if you are using an indexer cluster.


2. Assess Disk Performance
Each indexer should be able to search roughly 125,000 events/sec. The more events/second is better. Run the following search in Fast Mode (Last 4 hours is usually sufficient). Since we are using Fast Mode, this is almost a direct test of pure disk performance in searches.
index=_internal | stats count by splunk_server
Use the job inspector to see the number of events and how many seconds it took. If your results are below the expected numbers, then you should scroll down and see if one or more indexers are the root cause of the slow performance.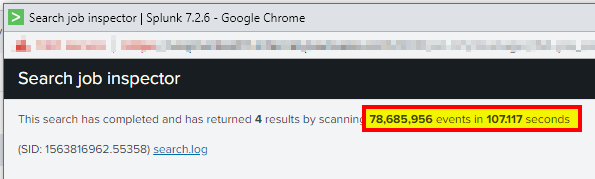
![\[\frac{78,685,956 \text{ events}}{107,117 \text{ seconds}} / 4 \text{ indexers} = \textbf{183,644 \text{events per second per indexer}}\]](https://www.pandatech.co/wp-content/ql-cache/quicklatex.com-563297e71c86967be6634cd222b86352_l3.png "Rendered by QuickLaTeX.com")
3. Identify Slow Indexers
If the issue is believed to be related to a specific (search peer), the below stanza can be used to troubleshoot. Add the below lines to the $SPLUNK_HOME/etc/system/local/limits.conf file. This does not require a splunk restart to take effect. Perform a search again, and use the job inspector to see detailed times on how long each action takes on an indexer. Remember to set it to false again after troubleshooting has been completed.
[search_metrics] debug_metrics = true
4. Assess CPU/Memory Performance
The expected performance for this search is roughly 5,000 events/sec. The more events/second is better. Run the following search in Smart Mode (Last 4 hours is usually sufficient, but use the same time frame as you used for your IOPS test):
index=_internal
Use the job inspector to see the number of events and how many seconds it took. If your results are below the expected numbers, then you should assess whether your search head has enough resources based on the number of users and scheduled searches. Further below are steps to guesstimate your scheduled search capacity.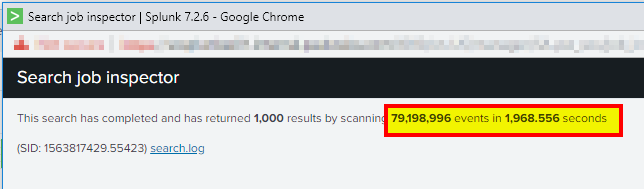
![\[\frac{78,198,966 \text{ events}}{1,968,556 \text{ seconds}} / 4 \text{ indexers} = \textbf{10,058 \text{events per second per indexer}}\]](https://www.pandatech.co/wp-content/ql-cache/quicklatex.com-fa9cef0a19f87c6e720061df8a463830_l3.png "Rendered by QuickLaTeX.com")
5. Guesstimate Scheduled Search Capacity
If your search issue may be related to CPU or Memory, it is most likely an issue on the Search Head. You can start by reviewing the number of users in your environment in addition to the number of scheduled searches configured. Scheduled search settings can be found in the $SPLUNK_HOME/etc/system/local/limits.conf file. See the below default settings and how search capacity can be roughly calculated based on the numbers.
[search] base_max_searches = 6 max_rt_search_multiplier = 1 max_searches_per_cpu = 1
Assuming the recommended 16 CPU core configuration and the above custom settings, you can see that the number of schedules searches is pretty limited. This is why there are often recommendations for much more CPU and RAM for Enterprise Security deployments.
![\[(16 \text{ CPU cores } \times 1 \text{ max searches per cpu}) + 6 \text{ base max searches} = \textbf{22 \text{total searches}}\]](https://www.pandatech.co/wp-content/ql-cache/quicklatex.com-1a49af3aab045cfee9ef1394c0e74ff0_l3.png "Rendered by QuickLaTeX.com")
![\[\lfloor 22 \text{ total searches} \times \frac{1}{2} \rfloor = \textbf{11 \text{scheduled searches}}\]](https://www.pandatech.co/wp-content/ql-cache/quicklatex.com-f1c771de6044ed23bd078c36fe571597_l3.png "Rendered by QuickLaTeX.com")
![\[11 \text{ scheduled searches} \times 1 \text{ max rt search multiplier} = \textbf{11 \text{real time scheduled searches}}\]](https://www.pandatech.co/wp-content/ql-cache/quicklatex.com-42bc7022cac97eefd51d589fbdaa08a6_l3.png "Rendered by QuickLaTeX.com")
![\[\lfloor 11 \text{ scheduled searches} \times \frac{1}{2} \rfloor = \textbf{5 \text{data model accelerations or summaries}}\]](https://www.pandatech.co/wp-content/ql-cache/quicklatex.com-25d4a44d8fc8e4b37903058fe5b71f66_l3.png "Rendered by QuickLaTeX.com")